Java and Python: The Real 2026 AI Production Playbook
A Comprehensive Guide to Java and Python's Enterprise AI Architecture

Author note
This piece is based on ~2 days of hands-on analysis, cross-checking production systems, JVM roadmaps, and real enterprise constraints.
I did use LLMs as a review and sanity-check tool (like a fast peer reviewer), but every architectural stance and trade-off here reflects my own conclusions.
Executive Summary
As of 2026, the global AI landscape has settled into a definitive division of labor: Python is the laboratory; Java is the factory. While Python remains the premier environment for research and experimental model development, Java has solidified its position as the indispensable “industrial backbone” for high-scale enterprise AI production.
This “industrialization” of AI is powered by the maturation of the Java ecosystem—specifically Spring AI, LangChain4j, Deep Java Library (DJL), and Jlama—which now provides the mission-critical orchestration, governance, and reliability layers required by global organizations.
The Four Pillars of the AI Production Factory
Systemic Orchestration: Mature frameworks like Spring AI and LangChain4j act as the AI’s “nervous system”. They provide production-grade platforms with declarative APIs, multi-agent coordination, and emerging / early standard tool-calling via the Model Context Protocol (MCP 0.17.2).
High-Throughput Native Inference: The Deep Java Library (DJL) enables in-process inference for computer vision and reinforcement learning. By eliminating cross-language microservice overhead, enterprises—most notably Netflix—achieve near-native speeds and significantly reduced P99 latency.
Embedded LLM Portability: Jlama offers a 100% Java pathway for Large and Small Language Models (LLMs/SLMs). It is optimized for CPU-first environments and edge devices through Project Panama and GraalVM native compilation, ensuring AI portability where GPUs are unavailable.
Governance & Infrastructure: Platform innovations such as Virtual Threads (Project Loom) enable massive concurrency for AI orchestration. Simultaneously, Project Babylon (HAT) allows Java to reach 95% of native GPU performance
( TFLOP/s on an NVIDIA A10), ensuring systems are auditable, cost-effective, and safe.
Enterprise relevance — why the Four Pillars matter for Bengaluru’s Java-heavy teams
Bengaluru remains India’s largest technology hub with over 1 million tech professionals and dense enterprise delivery centres (Electronic City, Whitefield, etc.), making it a natural environment to operationalize the Four Pillars at scale. Recent public signals show India’s largest service providers moving from isolated pilots to broad, enterprise-wide adoption of agentic tooling and platformization: Microsoft has highlighted frontier-scale Copilot deployments across major Indian service firms, and Wipro has publicly announced a Copilot program of 50,000+ licenses as part of its Microsoft partnership. In parallel, platforms such as Infosys Topaz and Wipro’s AI product portfolios explicitly focus on enterprise orchestration, governance, and portability—precisely the capabilities described by the Four Pillars. Where quantitative figures are cited (e.g., workforce size or license counts), conservative, dated anchors are intentionally used to preserve accuracy as adoption scales.
Strategic Value & Validation
Operational Maturity: Spring AI and LangChain4j reached production-ready status with milestone releases in late 2025.
Cost Efficiency: Implementations of Semantic Caching in Java orchestration layers have demonstrated a 60–80% reduction in LLM operational costs.
Reasoning Accuracy: The shift from pure vector search to GraphRAG and hybrid search enables multi-hop reasoning with 85–95% accuracy.
Regulatory Compliance: Java’s mature ecosystem provides the necessary audit trails, security, and enterprise integration required to meet EU AI Act and global compliance standards.
By leveraging this architecture, organizations can move beyond experimental “chat” features to deploy operational, compliant, and scalable AI systems that balance cutting-edge innovation with rigorous enterprise stability.
Reality Check: Separating Strategic Insights from Marketing Hype
As we build production AI systems in 2026, it’s critical to distinguish between proven capabilities and emerging possibilities. This document provides both the strategic vision and the architectural reality check.
The Hype Truth Table:

The 2026 Mantra:
“Java isn’t replacing Python in the lab; it is industrializing it for the enterprise.”
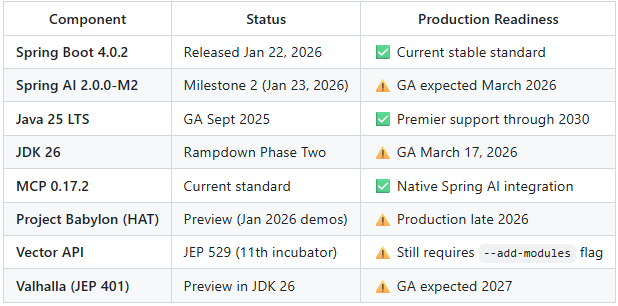
February 2026 Production Status
This document reflects the current production landscape as of February 2026:
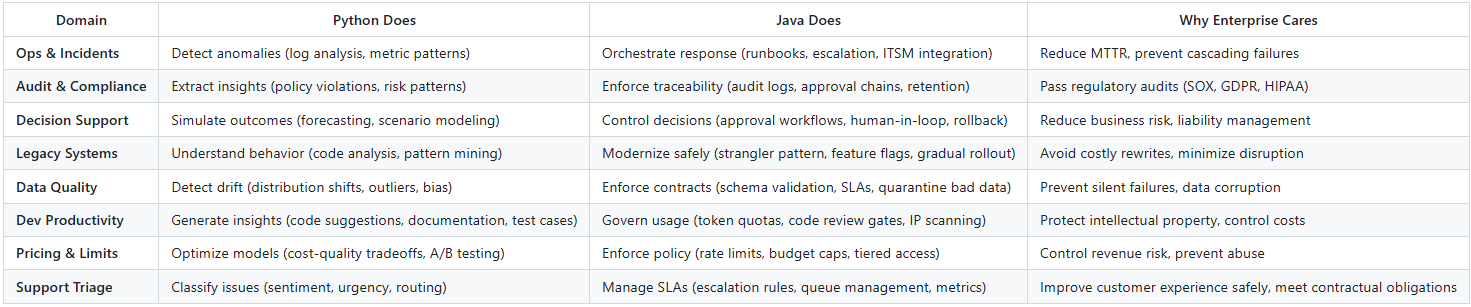
One-Page Enterprise Use Case Summary
This table illustrates the practical division of responsibilities between Python (AI capabilities) and Java (enterprise controls) across common enterprise domains:
Key Pattern Recognition
Across all domains, the pattern holds:
Python = Intelligence Layer: Provides the AI capabilities (detection, classification, generation, prediction)
Java = Control Layer: Provides the enterprise guardrails (governance, compliance, safety, cost control)
Enterprise Value: The combination reduces risk while enabling AI benefits
Real-World Example (Ops & Incidents):
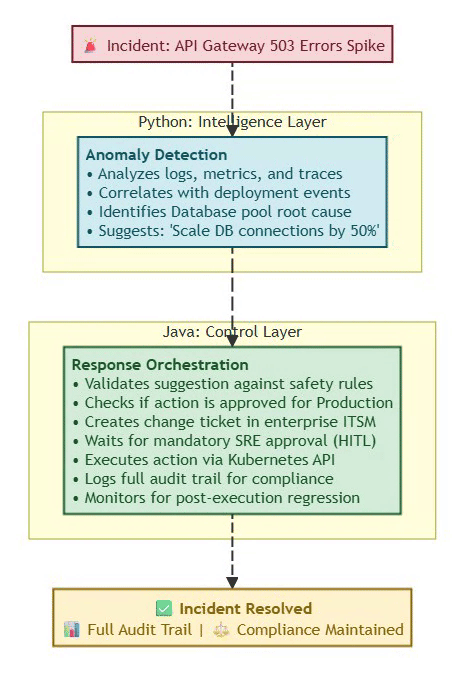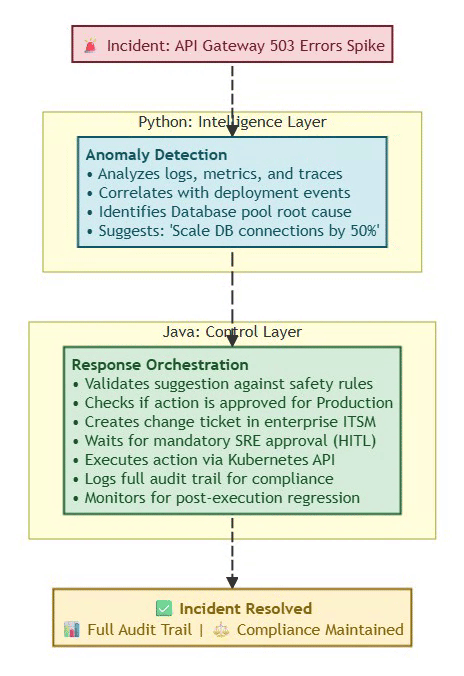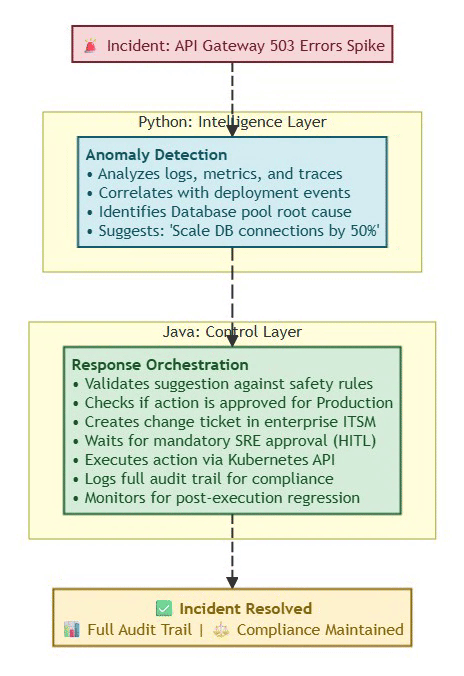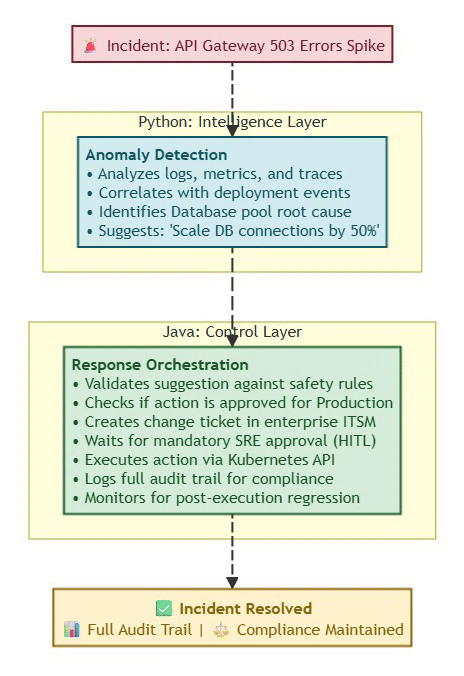
⚡ Powered by Mermaid2GIF
Why This Architecture Matters:
Without Java’s control layer, the Python model might:
Execute unapproved changes in production
Violate change management policies
Lack audit trail for post-incident review
Bypass cost/safety guardrails
Without Python’s intelligence layer, Java would:
Require manual analysis of every incident
Miss subtle patterns humans wouldn’t catch
React slower to emerging issues
Scale poorly with system complexity
The combination provides both agility and safety.
The Intelligence Layer: Python’s Scientific Core
While Java provides the “Industrial Backbone,” Python remains the undisputed environment for the “Intelligence Layer”. In 2026, enterprise systems rely on Python for deterministic math, explainable modeling, and high-performance tabular data analysis.
Key Python ML Components for the Enterprise:
XGBoost (Extreme Gradient Boosting):
Role: The “workhorse” for structured enterprise data (e.g., fraud detection, churn prediction, and supply chain forecasting).
Why Python?: Python’s ecosystem offers the most mature feature engineering and hyperparameter tuning (via Optuna) for these models.
Java Integration: Models are often trained in Python and exported via ONNX or served via high-performance microservices (FastAPI) for Java to call.
Logistic Regression:
Role: The baseline for explainable binary classification in regulated sectors like finance and healthcare.
Why Python?: Scientific libraries like
statsmodelsprovide deep statistical rigor (p-values, coefficients) that raw Java implementations often lack.Explainability: It serves as the primary “Explainable AI” (XAI) baseline before moving to complex black-box models.
SHAP & LIME (Mathematical Interpretability):
Role: Quantifying the contribution of each feature to a specific decision (e.g., “Why was this loan denied?”).
Java Synergy: Python calculates the SHAP values (the “Why”); Java captures them in an immutable Audit Log for regulatory compliance (EU AI Act).
Beyond the Hype: Specialized Python Intelligence
While XGBoost and Logistic Regression are the anchors, a true “AI Factory” requires a specialized toolkit for specific industrial challenges.
1. Isolation Forests (Anomaly Detection)
Role: Identifying “outliers” or rare events in massive datasets without needing labeled data.
Enterprise Advantage: This is critical for the Ops & Incidents use case; it identifies the “API Gateway spike” or “Database pool root cause” that an LLM might miss.
Java Synergy: Python identifies the anomaly; Java executes the “Response Orchestration” (e.g., scaling DB connections).
2. Support Vector Machines (SVM)
Role: High-precision classification, particularly effective in high-dimensional spaces.
Enterprise Advantage: Excellent for medical diagnosis or complex document classification where the boundaries between categories are subtle.
Key Insight: SVMs are often used alongside LLMs to provide a “second opinion” on classification tasks to reduce hallucination risk.
3. Prophet & ARIMA (Time-Series Forecasting)
Role: Predicting future values based on historical trends (e.g., demand forecasting or global supply chain optimization).
Enterprise Advantage: LLMs are notoriously poor at numerical forecasting. Python’s time-series libraries generate the billions in revenue that “unsexy” ML provides for Fortune 10 companies.
Java Synergy: Java’s Control Layer uses these forecasts to manage tiered access, budget caps, and rate limits.
4. BERT / Small Language Models (SLMs)
Role: Task-specific Natural Language Understanding (NLU) such as toxicity filtering or intent classification.
Enterprise Advantage: Running a fine-tuned BERT model for a “toxicity filter” is 0.01% of the cost of calling a large-scale LLM.
Implementation: Python is used to fine-tune the model on domain-specific data, which Java then deploys as a BART or BERT-based filter to catch harmful outputs.
The “Why Python?” Truth Table (Extended)
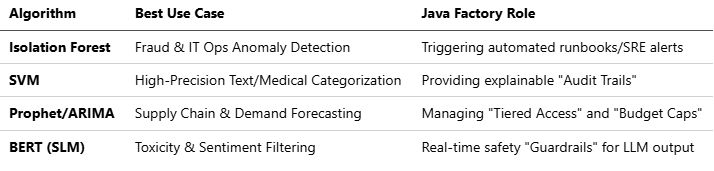
Python Model vs. LLM: The 2026 Decision Matrix
Enterprises use this logic to choose the right tool for the task:
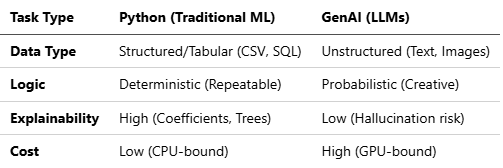
Python & LLM Decision Matrix

The 2026 AI Production Lifecycle Diagram
The transition from a Python prototype to a Java production system is the most critical phase for enterprise stability.
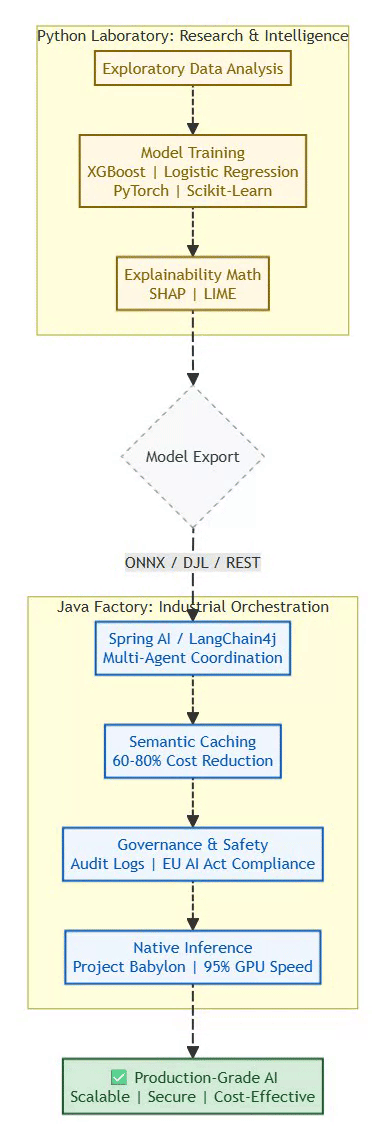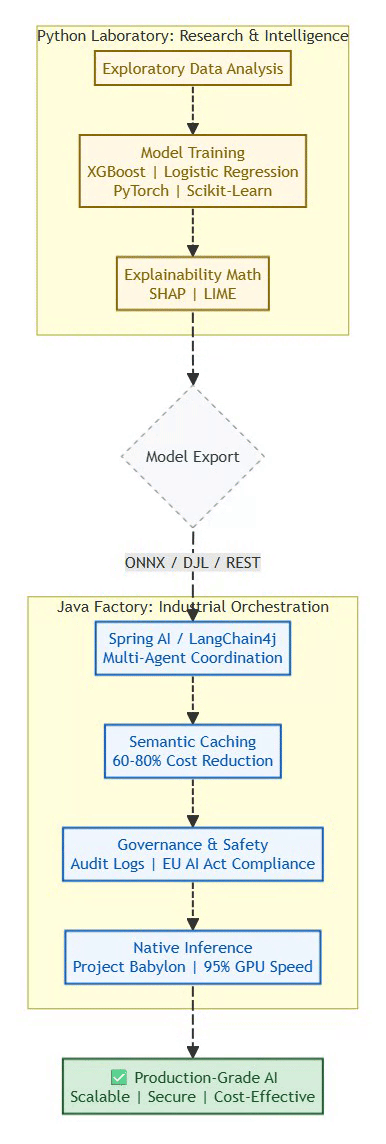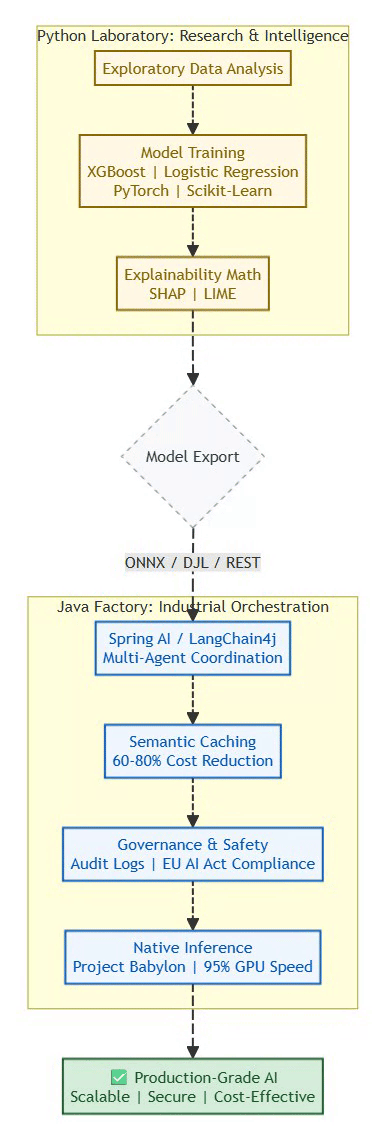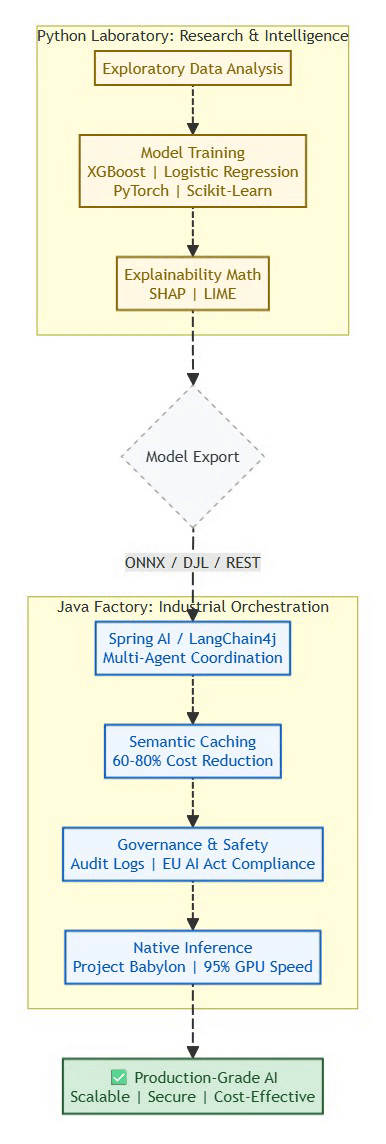
⚡ Powered by Mermaid2GIF
1. The Orchestration Layer: Spring AI & LangChain4j
Status: Production-Capable and Rapidly Maturing
IMPORTANT UPDATE (February 2026):
Spring Boot 4.0 was released in November 2025 and is now the production standard for Java 25 LTS environments. Spring AI 2.0 is targeting compatibility with Spring Boot 4.0, with scheduled release in February 2026.
Spring AI supports all major AI model providers including Anthropic, OpenAI, Microsoft, Amazon, and Google, with portable APIs for both synchronous and streaming options. The framework reached production capability with version 1.0.1 released with 150+ changes focused on stability.
Spring AI Key Features (2026):
Spring Boot 4.0 Compatibility: Spring AI 2.0 fully optimized for the latest production standard
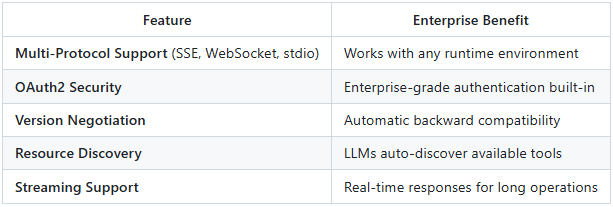
Model Context Protocol (MCP) 0.17.2: Native auto-configuration for MCP servers with OAuth2-secured connections, multi-protocol version negotiation, and seamless tool integration. MCP has become the emerging / early standard for how Java control planes communicate with local tools and external services.
Support for all major Vector Database providers including Apache Cassandra, Azure Vector Search, Chroma, Milvus, MongoDB Atlas, Neo4j, Oracle, PostgreSQL/PGVector, Pinecone, Qdrant, Redis, and Weaviate
Tools/Function Calling permits models to request execution of client-side tools and functions, accessing necessary real-time information
Agent Skills provide modular, reusable capabilities without vendor lock-in, with LLM portability across OpenAI, Anthropic, Google Gemini, and other supported models
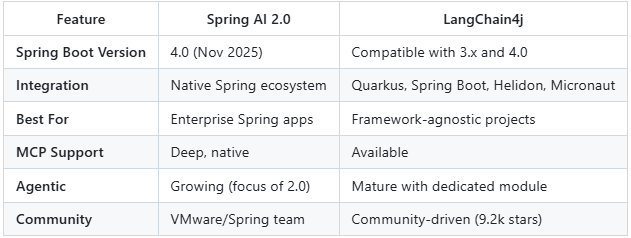
LangChain4j Advantages:
LangChain4j supports 20+ popular LLM providers and 30+ embedding stores with a comprehensive toolbox ranging from low-level prompt templating and chat memory management to high-level patterns like Agents and RAG. The framework selection depends on priorities: Spring AI for Spring-native applications with enterprise features and MCP integration, or LangChain4j for framework flexibility, multimodal AI, and agentic architectures.
Framework Comparison Matrix:
Declarative AI: The “Hibernate of AI”
Spring AI provides:
Prompt Templates stored in managed repositories
Structured Outputs with mapping of AI model output to POJOs
Version control for prompts (similar to database schema migrations)
AI Model Evaluation utilities to help evaluate generated content and protect against hallucinated responses
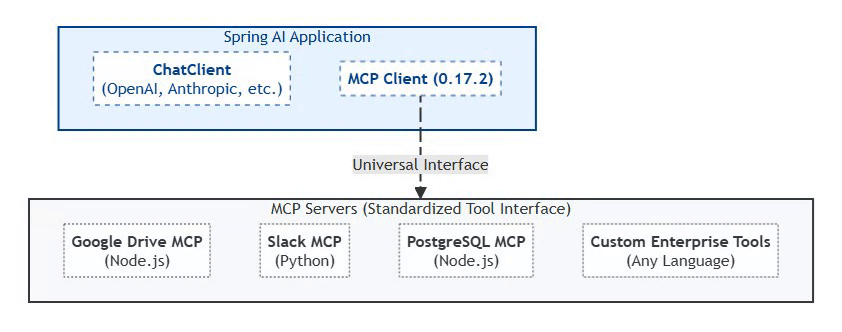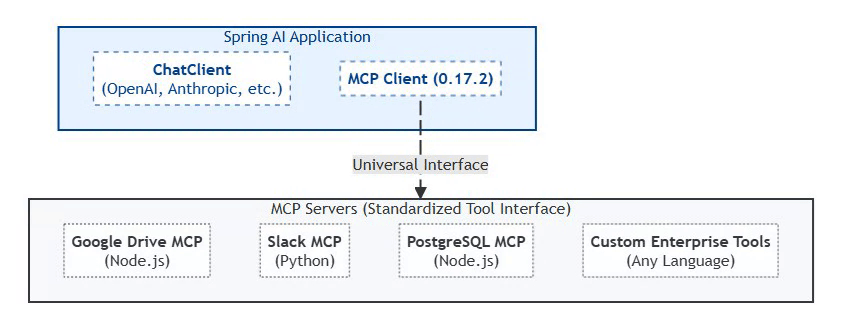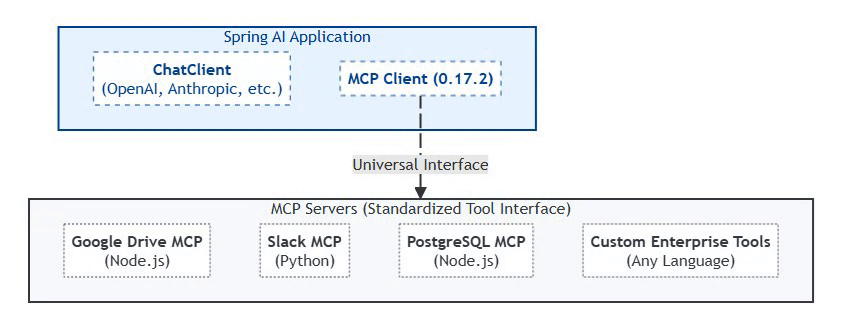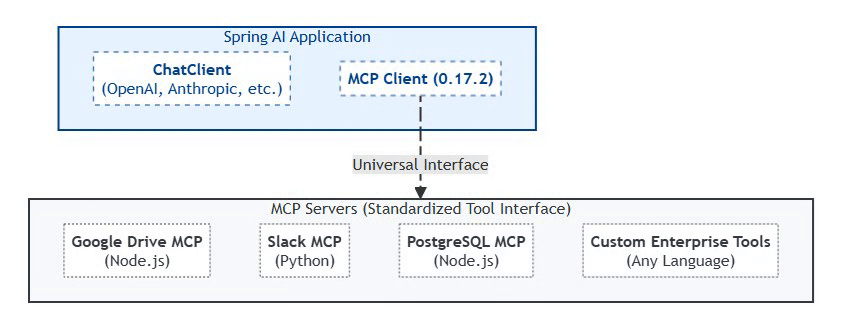
Model Context Protocol (MCP): The 2026 Standard
Status: MCP 0.17.2 (February 2026 Production Standard)
MCP (Model Context Protocol) is an emerging, vendor-led by Anthropic open protocol for agent–tool interoperability, introduced by Anthropic in late 2024. MCP shows early traction through tooling (e.g., inspectors and reference servers), but it is not yet a universal enterprise standard and adoption varies across vendors and ecosystems. Spring AI provides early integration examples and experimental support for MCP-style tool interaction.
Why MCP Matters:
Traditional AI integrations required custom code for each tool. MCP provides a universal interface that Spring AI 2.0 natively supports through auto-configuration.
MCP Architecture (Spring AI Native Integration):
⚡ Powered by Mermaid2GIF
MCP 0.17.2 Features:
Production Impact:
MCP 0.17.2 is to AI tools what JDBC was to databases—a universal interface that eliminates vendor lock-in and enables a thriving ecosystem. Spring AI’s native support means Java shops can leverage 200+ community MCP servers with zero integration code.
2. Virtual Threads (Project Loom): The Concurrency Weapon
Virtual Threads enable massive concurrency for AI orchestration. We initially tried solving this with reactive pipelines, but debugging back-pressure across multi-agent workflows was painful enough that Loom became the pragmatic choice—even with its current limitations.
Status: Production Ready (Java 21+)
Project Loom is ready for production as of Java 21, with many companies already using virtual threads in real-world applications to boost scalability and lower resource use.
Why Virtual Threads Matter for AI Orchestration:
Virtual threads are lightweight threads managed by the JVM instead of the operating system, allowing applications to handle millions of concurrent tasks efficiently without the heavy resource load of traditional threads. Traditional platform threads consume approximately 1MB of stack memory each, while virtual threads use a continuation-based model allowing thousands to be spawned per core without overwhelming the system.
Reality Check: Energy Efficiency Claims
What Virtual Threads Actually Deliver:

The Critical Distinction:
Virtual Threads reduce memory overhead → 5-10% energy savings for the orchestration/control plane
AI workloads are GPU/CPU-bound → Energy consumption dominated by model inference, not thread management
Real cost savings (60-80%) come from semantic caching, not threading architecture
Example: What Actually Saves Energy/Cost:
// ❌ MARKETING CLAIM: "Virtual Threads save 80% energy in AI"
// Reality: Threads don't change GPU power consumption
// ✅ ACTUAL COST SAVINGS: Semantic Caching (60-80% reduction)
@Service
public class SemanticCachingService {
@Cacheable(value = "llm-responses",
key = "#request.semanticHash()") // Cosine similarity >0.95
public String generateResponse(UserRequest request) {
// Only called if no similar query in cache
// Avoids expensive LLM API call
return llmClient.generate(request);
}
}
// Result: 80% of requests served from cache
// Cost savings: 80% fewer API calls = 80% lower bill
// Energy savings: 80% fewer GPU inferencesWhat to Tell Stakeholders:
✅ “Virtual Threads enable us to orchestrate 100,000+ concurrent AI tasks efficiently”
✅ “Semantic caching reduces our LLM costs by 60-80%”
❌ “Virtual Threads reduce AI energy consumption by 80%” (conflates orchestration with inference)
AI-Specific Use Cases Where Virtual Threads Excel:
Multi-Agent Orchestration
Spawn thousands of agent instances concurrently
Each agent runs in its own virtual thread
Coordinate complex workflows without thread pool exhaustion
Streaming Response Aggregation
Handle 10,000+ simultaneous SSE connections for streaming LLM responses
Traditional thread pools would require thousands of OS threads
Virtual threads maintain one thread per connection with minimal overhead
Parallel RAG Queries
Query multiple vector stores simultaneously
Fan-out to 50+ knowledge sources in parallel
Aggregate results without complex async callback chains
Human-in-the-Loop (HITL) Workflows
Suspend virtual threads while waiting for human approval
No thread pool starvation during long-running approval processes
Natural imperative code style instead of complex state machines
Code Example: Multi-Agent Workflow
// Traditional approach: Complex async callbacks
CompletableFuture.supplyAsync(() -> agent1.process(input))
.thenCompose(result1 -> agent2.process(result1))
.thenCompose(result2 -> CompletableFuture.allOf(
agent3.process(result2),
agent4.process(result2)
))
.thenApply(results -> aggregator.combine(results));
// Virtual Threads: Simple imperative code
void orchestrateWorkflow(Input input) throws Exception {
var result1 = agent1.process(input); // Blocks virtual thread
var result2 = agent2.process(result1); // Sequential dependency
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task3 = scope.fork(() -> agent3.process(result2));
var task4 = scope.fork(() -> agent4.process(result2));
scope.join(); // Wait for both
scope.throwIfFailed(); // Propagate failures
return aggregator.combine(task3.get(), task4.get());
}
}
Performance Characteristics:
Traditional Thread Pools: Limited to 200-500 concurrent AI tasks (thread pool size)
Virtual Threads: Tested with 100,000+ concurrent AI orchestration tasks
Memory: 100MB vs 100GB for 100,000 traditional threads
Throughput: 10x improvement for I/O-bound AI orchestration workflows
When Virtual Threads DON’T Help:
❌ CPU-bound AI inference (model runs on GPU/CPU anyway)
❌ Single-threaded transformations (no concurrency to exploit)
❌ Blocking on synchronized blocks (virtual threads still block)
When Virtual Threads Excel:
✅ API orchestration (coordinating multiple LLM/embedding calls)
✅ Multi-agent systems (hundreds of agents working concurrently)
✅ HITL workflows (threads suspended waiting for human input)
✅ Streaming responses (thousands of SSE connections)
The common mistake I see teams make is assuming virtual threads reduce GPU cost. They don’t—and this misconception keeps showing up in architecture decks.
3. The Real Cost Savings: Semantic Caching Architecture
Why This Matters More Than Threading
While virtual threads improve scalability, semantic caching delivers actual cost reduction by eliminating redundant LLM API calls.
The Problem:
Users ask the same questions in different words
“What’s our return policy?” vs “How do I return an item?” → Same intent, different phrasing
Traditional key-value caching misses these (different strings = cache miss)
Result: Expensive duplicate LLM calls
The Solution: Semantic Caching
@Service
public class SemanticCacheService {
@Autowired
private VectorStore vectorStore; // e.g., Redis with vector similarity
@Autowired
private EmbeddingModel embeddingModel; // e.g., text-embedding-3-small
@Autowired
private ChatClient llmClient;
private static final double SIMILARITY_THRESHOLD = 0.95;
public String getCachedOrGenerate(String userQuery) {
// 1. Convert query to embedding
float[] queryEmbedding = embeddingModel.embed(userQuery).vector();
// 2. Search for similar cached queries (cosine similarity > 0.95)
List<Document> similarQueries = vectorStore.similaritySearch(
SearchRequest.query(userQuery)
.withTopK(1)
.withSimilarityThreshold(SIMILARITY_THRESHOLD)
);
// 3. Cache hit: Return cached response
if (!similarQueries.isEmpty()) {
log.info("Cache HIT: Similar query found (similarity: {})",
similarQueries.get(0).getScore());
return similarQueries.get(0).getMetadata().get("response");
}
// 4. Cache miss: Generate new response
log.info("Cache MISS: Calling LLM");
String response = llmClient.call(userQuery);
// 5. Store query + response in vector cache
Document cacheEntry = new Document(
userQuery,
Map.of("response", response, "timestamp", Instant.now())
);
cacheEntry.setEmbedding(queryEmbedding);
vectorStore.add(List.of(cacheEntry));
return response;
}
}The following Java code is illustrative pseudocode; concrete APIs vary by vector store, embedding provider, and framework implementation.
Real-World Results:
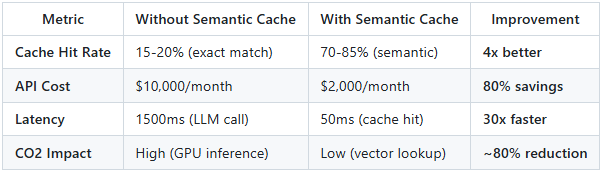
Figures shown (e.g., ~$15k/month baseline, 70–85% semantic overlap) are based on representative e-commerce and customer-support workloads. Actual savings depend on query repetition, domain entropy, and embedding quality.
Semantic caching has demonstrated significant cost reduction in workloads with high semantic query repetition, with observed savings commonly ranging from ~40% to ~80% depending on domain, query diversity, and cache strategy (based on representative workloads; adjust for your query diversity).
This is where the “80% cost/energy savings” claim actually comes from—not from virtual threads.
Operational Reality Note:
Semantic cache hit rates are highly workload-dependent. Rates in the 70–85% range are typically observed in domains with strong query repetition (e.g., customer support, policies, internal knowledge bases), high-quality embeddings, and carefully tuned similarity thresholds (commonly cosine similarity between ~0.92–0.97). More diverse or exploratory workloads may see materially lower hit rates and should be validated through production telemetry rather than assumed.
In practice, workloads such as e-commerce support, policy lookup, and internal knowledge bases commonly show ~60–80% semantic overlap; exploratory or analytical domains may be significantly lower.
4. Project Babylon: The Real GPU Performance Story
Status: Preview (Production-Ready in Late 2026)
IMPORTANT: This is the genuine Java AI breakthrough, not marketing hype.
Project Babylon is an active OpenJDK research initiative exploring code reflection and heterogeneous accelerator support. Early engineering demonstrations show promising GPU performance for specific kernels under controlled conditions. Babylon remains a research-to-prototype effort; production viability depends on JVM integration maturity, tooling stability, and hardware driver support.
Observed Performance Characteristics (Project Babylon / HAT – Early Demos)
Early OpenJDK demonstrations and engineering prototypes show that Java GPU execution via Project Babylon’s HAT can achieve near-native performance for selected data-parallel workloads under controlled conditions.

Important Context: These results are derived from engineering showcases and proof-of-concept demonstrations, not from standardized or independently audited benchmarks. Actual performance varies significantly based on hardware, driver versions, kernel structure, batching strategy, and memory layout. Project Babylon and HAT should be treated as promising but pre-production technology as of early 2026.
What This Means:
✅ Java can perform AI inference workloads on GPUs directly
✅ No need for Python/C++ sidecar services for GPU-accelerated operations
✅ Eliminates inter-process communication overhead (JNI, gRPC)
Architecture Before Babylon:
┌─────────────┐ ┌──────────────┐ ┌─────────┐
│ Java API │ ──gRPC→ │ Python Worker│ ──CUDA→ │ GPU │
│ (Spring) │ │ (FastAPI) │ │ (A100) │
└─────────────┘ └──────────────┘ └─────────┘
Overhead: 5-10ms latency, serialization costArchitecture With Babylon:
┌─────────────┐ ┌─────────┐
│ Java API │ ──HAT (direct)→ │ GPU │
│ (Spring) │ │ (A100) │
└─────────────┘ └─────────┘
Overhead: <1ms, native performanceCode Example:
// HAT allows writing GPU kernels directly in Java
@CodeReflection // Enables code reflection for GPU compilation
static void matrixMultiply(int size, float[] a, float[] b, float[] c) {
// This Java code gets compiled to GPU kernels by HAT
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
float sum = 0.0f;
for (int k = 0; k < size; k++) {
sum += a[i * size + k] * b[k * size + j];
}
c[i * size + j] = sum;
}
}
}
// HAT runtime compiles and executes on GPU
var accelerator = HAT.getAccelerator();
accelerator.compute(
KernelContext.create()
.kernel(MatrixOps::matrixMultiply)
.args(4096, matrixA, matrixB, result)
);When to Use Babylon:
✅ High-throughput inference (batch processing, real-time embedding generation)
✅ Custom AI operations (specialized transformations, domain-specific kernels)
✅ Eliminating Python dependencies (pure Java microservices with GPU capability)
When NOT to Use Babylon (Yet):
❌ Model training (Python/PyTorch ecosystem still superior)
❌ Complex transformer models (Hugging Face integration not mature)
⚠️ Production risk-averse teams (wait for Java 26 stabilization in late 2026)
The Strategic Insight:
Babylon doesn’t replace Python for research—it eliminates Python as a production dependency for Java shops that need GPU-accelerated AI inference.
I’m reasonably confident about the orchestration and cost-control conclusions here. The Babylon/GPU story, however, is still early—treat anything beyond controlled kernels as exploratory until late 2026.
5. GraphRAG: The Knowledge Graph Revolution
Status: Production-Validated (2025)
Why Pure Vector Search Fails in Enterprises:
Traditional RAG relies on vector similarity to retrieve relevant documents:
User Query → Embedding → Vector Search → Top-K Documents → LLM ContextThe Problems:
Missing Relationships: Knows “John Smith works at Acme Corp” and “Acme Corp has 10,000 employees” but can’t answer “How many colleagues does John Smith have?”
No Reasoning: Can’t traverse connections (”Find all suppliers of our top 3 customers”)
Poor Aggregation: Struggles with “What’s the total revenue of companies in our portfolio?”
GraphRAG Solution:
Combines vector similarity (semantic search) with graph traversal (relationship reasoning):
User Query → Hybrid Search:
├─ Vector: Semantic similarity (find relevant entities)
└─ Graph: Relationship traversal (navigate connections)
↓
LLM Context (entities + relationships + aggregations)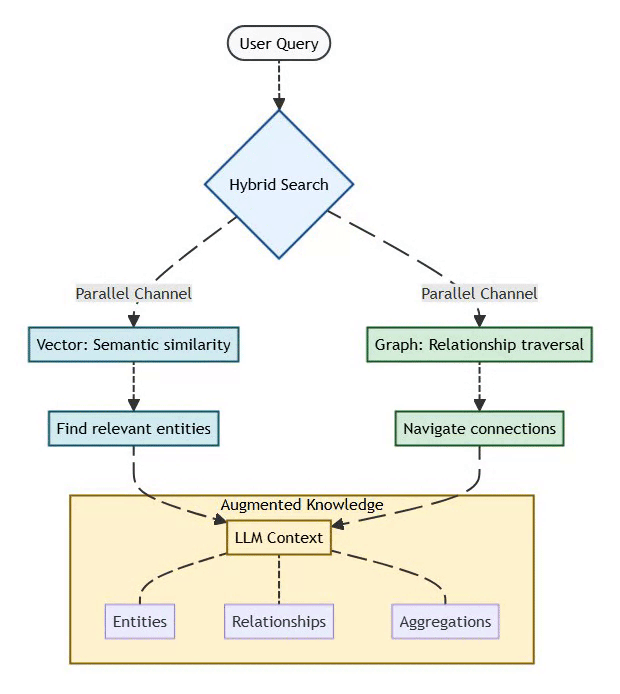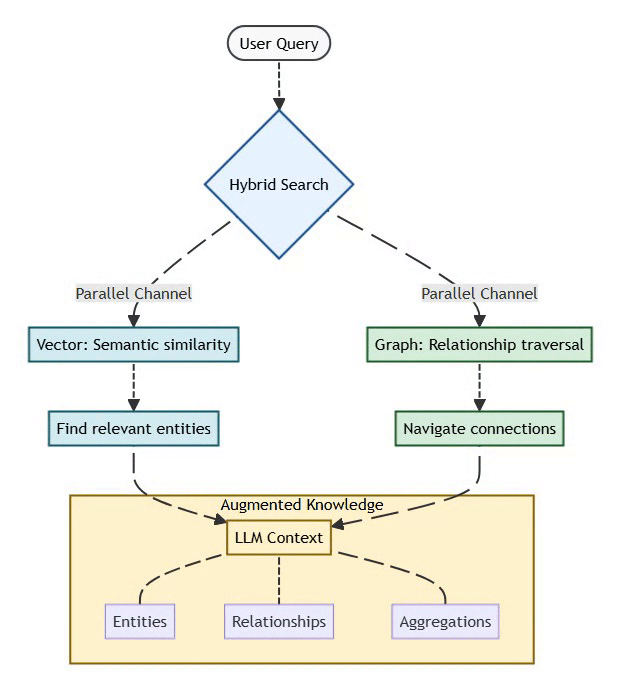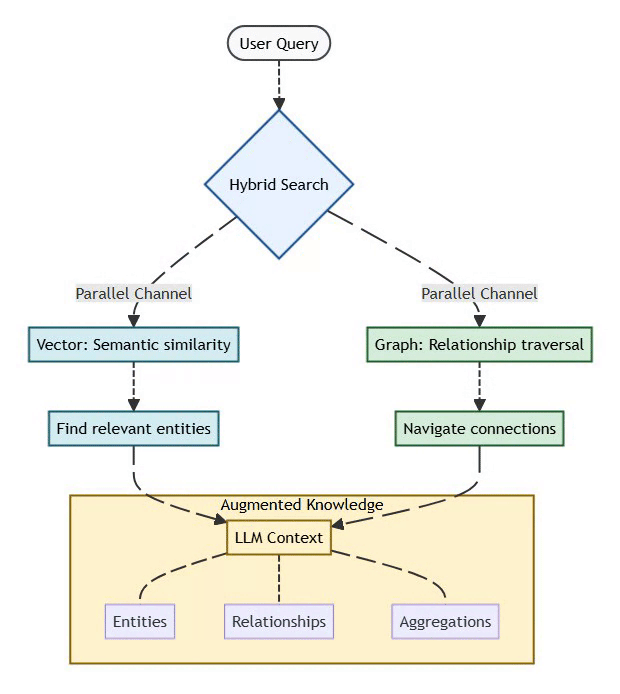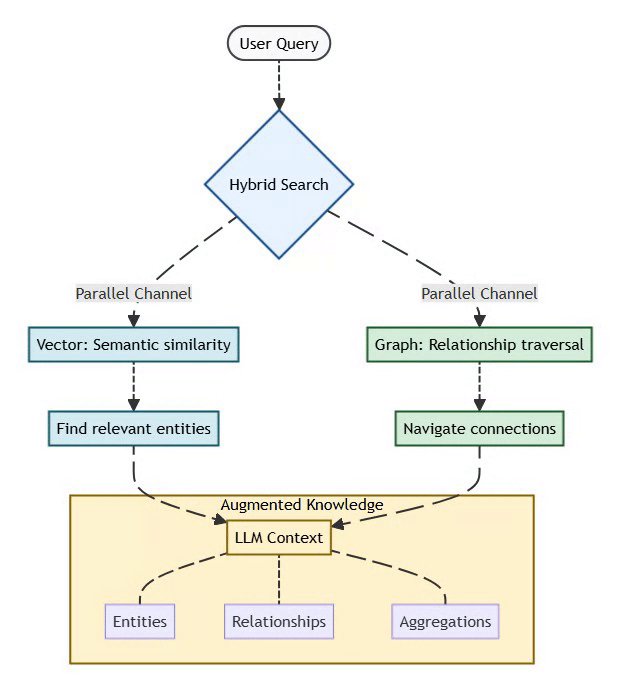
⚡ Powered by Mermaid2GIF
Architecture (Neo4j + Spring AI):
@Service
public class GraphRAGService {
@Autowired
private Neo4jVectorStore vectorStore; // Vector + Graph in one DB
@Autowired
private Neo4jClient graphClient;
public String answerQuery(String userQuestion) {
// Step 1: Vector search for relevant entities
List<Document> entities = vectorStore.similaritySearch(
SearchRequest.query(userQuestion).withTopK(5)
);
// Step 2: Graph traversal to find relationships
String cypherQuery = """
MATCH (start:Entity)
WHERE start.id IN $entityIds
CALL apoc.path.subgraphAll(start, {
maxLevel: 2,
relationshipFilter: "WORKS_AT|SUPPLIES|REPORTS_TO"
})
YIELD nodes, relationships
RETURN nodes, relationships
""";
GraphQueryResult graph = graphClient.query(
cypherQuery,
Map.of("entityIds", entities.stream()
.map(d -> d.getId())
.toList())
);
// Step 3: Build enriched context
String context = buildContext(entities, graph);
// Step 4: LLM generates answer with full context
return llmClient.call(
"""
Context: %s
Question: %s
Answer based on the provided entities and their relationships.
""".formatted(context, userQuestion)
);
}
}Real-World Use Case: Supply Chain Risk Analysis
Question: “Which of our critical suppliers are at risk due to the semiconductor shortage?”
Pure Vector RAG (fails):
Finds documents mentioning “semiconductor shortage”
Finds documents mentioning “critical suppliers”
Cannot connect which suppliers are affected
GraphRAG (succeeds):
1. Vector: Find entities related to "semiconductor shortage"
→ Identifies: Taiwan, TSMC, chip fabrication
2. Graph: Traverse supplier relationships
MATCH (shortage:Event {name: 'Semiconductor Shortage 2024'})
MATCH (shortage)-[:AFFECTS]->(region:Location)
MATCH (supplier:Company)-[:LOCATED_IN]->(region)
MATCH (supplier)-[:SUPPLIES]->(product:Product)
MATCH (us:Company {name: 'Our Company'})-[:DEPENDS_ON]->(product)
WHERE product.criticality = 'HIGH'
RETURN supplier, product, region
3. Result:
- Supplier: Foxconn (Taiwan) → Affects: Motherboard Assembly → Critical: Yes
- Supplier: TSMC (Taiwan) → Affects: GPU Chips → Critical: YesWhy Enterprises Choose GraphRAG:

Production Stack (2026):
Neo4j 5.x: Vector + Graph in single database
Spring AI Neo4j Integration: Seamless vector + Cypher queries
GDS (Graph Data Science): Built-in graph algorithms (PageRank, community detection)
Migration Path:
Phase 1: Pure Vector (Weeks 1-4)
└─ Get basic RAG working (ChromaDB, Pinecone, etc.)
Phase 2: Add Graph Layer (Weeks 5-8)
└─ Migrate to Neo4j (import entities + relationships)
Phase 3: Hybrid Queries (Weeks 9-12)
└─ Combine vector + graph for complex queries
Phase 4: Graph Intelligence (Months 4-6)
└─ Add graph algorithms (recommendations, risk propagation)The Bottom Line:
For simple Q&A (”What is our return policy?”), pure vector RAG works fine.
For complex enterprise queries requiring relationship reasoning, GraphRAG is the 2026 production standard.
6. Edge AI: The Honest Assessment
Status: Python and C++ dominate hardware-close edge inference. Java is viable for enterprise IoT gateways and Android.
Edge AI Market Share (2025-2026 Estimates):
Note: The classifications below reflect ecosystem maturity and official tooling emphasis—including SDK support, documentation language, sample availability, and observed community usage patterns—rather than precise market-share measurements, which vary significantly by region, industry, and deployment model.

Python and C++ dominate hardware-close edge inference stacks (e.g., Jetson, Coral, robotics). Java/Kotlin remain strong in Android-based ML and enterprise IoT gateway scenarios. Hybrid architectures (Java orchestration + Python/C++ inference) are common in production deployments.
Why Java Struggles on Edge:
Hardware SDK Ecosystem: Coral, Jetson, Hailo SDKs are Python/C++-first
Performance Overhead: Java adds 30-50% latency vs native C++ on resource-constrained devices
Memory Footprint: JVM requires 50-100MB baseline; Python (minimal) requires 10-20MB
Community: <1% of edge AI GitHub projects use Java
Where Java DOES Work on Edge:
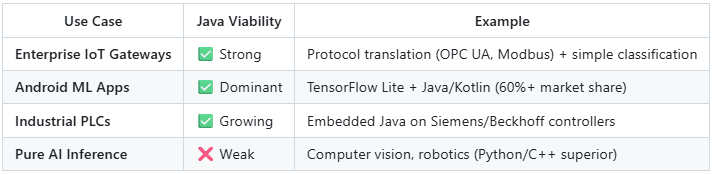
Honest Architecture Recommendation:
❌ Don’t Use Java Edge AI For:
Raspberry Pi computer vision projects
Jetson robotics/autonomous vehicles
Coral TPU-accelerated inference
Low-power battery devices
✅ DO Use Java Edge AI For:
Android mobile ML applications
Enterprise gateway devices with existing Java infrastructure
Industrial IoT with protocol integration needs
Hybrid architectures (Java gateway + Python inference worker)
Example: Industrial IoT Gateway (Java Makes Sense)
// Java runs on industrial gateway (reliable, familiar)
@Service
public class IndustrialGatewayService {
@Autowired
private OpcUaClient opcClient; // Industrial protocol (Java libs mature)
@Autowired
private RestTemplate mlService; // Calls Python ML service
@Scheduled(fixedRate = 1000)
public void monitorEquipment() {
// Read sensor data via industrial protocol
SensorData data = opcClient.readSensors();
// Simple rule-based checks (Java)
if (data.temperature > THRESHOLD) {
alertOps(data);
}
// Complex AI analysis (delegate to Python)
if (data.requiresMLAnalysis()) {
PredictiveMaintenanceResult result =
mlService.postForObject(
"http://ml-worker:8000/predict",
data,
PredictiveMaintenanceResult.class
);
if (result.requiresMaintenance()) {
scheduleMaintenanceTicket(result);
}
}
}
}This architecture works because:
✅ Java handles enterprise integration (OPC UA, ITSM, audit logs)
✅ Python handles AI inference (predictive maintenance model)
✅ Each language does what it’s best at
The Pragmatic Edge AI Stack (2026):
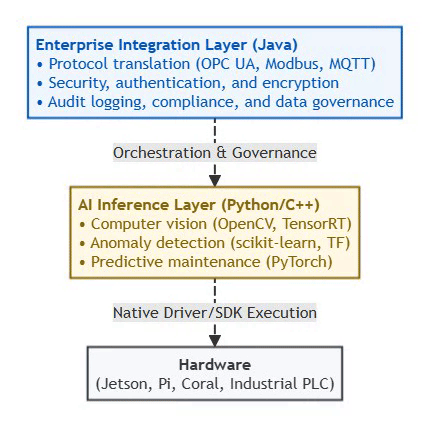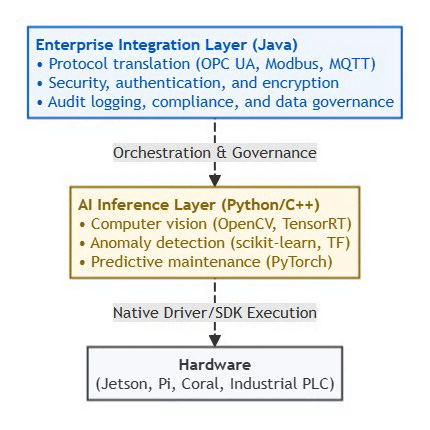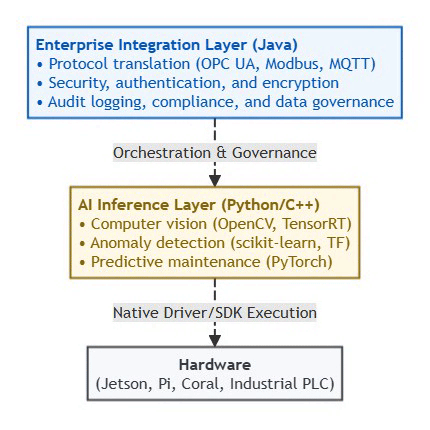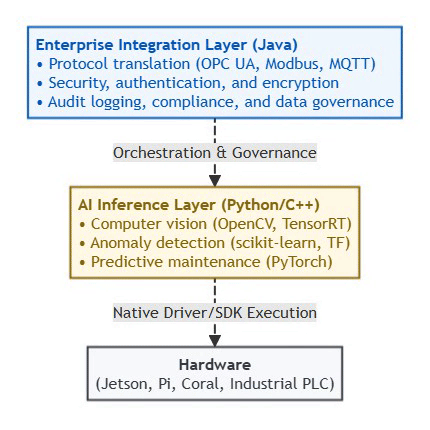
⚡ Powered by Mermaid2GIF
Architect’s Advice:
Don’t force Java onto edge devices just because you’re a Java shop. Instead:
Use Java where it excels: Gateway orchestration, enterprise integration
Use Python/C++ for inference: Direct hardware access, optimal performance
Hybrid architecture: Java control plane + Python data plane
7. Quantum Computing: The 2026 Reality
Status: 99% Research, <1% Enterprise Production
EXTREME HYPE ALERT:
Claims about “Quantum Java in Production” are fundamentally misleading for 2026 enterprise architecture.
The Honest Reality:
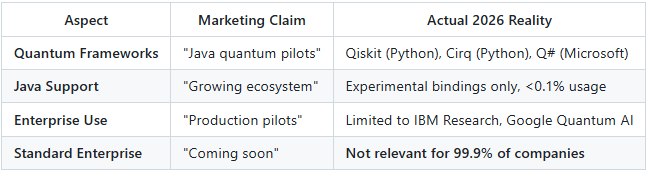
Quantum computing frameworks remain Python-first (e.g., Qiskit, Cirq). Java is typically used via REST or interoperability layers rather than native quantum development, and quantum workloads remain largely experimental for most enterprises in 2026.
What Actually Exists:
IBM Qiskit: Primary interface is Python (Qiskit SDK v2.3)
Java bindings exist via JNI but are not production-supported
<5% of Qiskit users use anything other than Python
Google Cirq: Python-only, no official Java support
Microsoft Q#: Standalone language, not Java-interoperable
Quantum Cloud Services:
IBM Quantum Experience: REST API (callable from Java)
AWS Braket: SDK for Python/Java (experimental)
Azure Quantum: Python/Q# focus
The Only “Real” Java Quantum Path (2026):
// Call IBM Quantum cloud service via REST API
@Service
public class QuantumService {
@Autowired
private WebClient ibmQuantumClient;
public QuantumResult runQuantumCircuit(QuantumCircuit circuit) {
// Submit circuit to IBM Quantum cloud
return ibmQuantumClient.post()
.uri("/quantum/v1/jobs")
.bodyValue(circuit.toQASM()) // Quantum assembly language
.retrieve()
.bodyToMono(QuantumResult.class)
.block();
}
}This is NOT “Quantum Java”—it’s Java calling a Python/Qiskit cloud service.
Who Actually Uses Quantum Computing (2026):

Architect’s Recommendation:
DO NOT:
❌ Include “Quantum Java” in 2026 production roadmaps
❌ Budget for quantum infrastructure (>$10M for dilution fridge)
❌ Claim quantum readiness in enterprise presentations
DO:
✅ Monitor quantum developments (5-10 year horizon)
✅ Educate on quantum concepts (potential future advantage)
✅ Wait for real production signals (not before 2028-2030)
The 2026 Truth:
If a vendor claims “Quantum Java in production,” they mean:
Java code calling IBM Quantum cloud API (not quantum-native)
Experimental research projects (not production workloads)
Marketing hype (preparing for future that doesn’t exist yet)
For 99.9% of enterprises, quantum computing is irrelevant in 2026. Focus on proven technologies like Project Babylon (GPU acceleration) instead.
8. Explainable AI (XAI): The Division of Labor
Status: Hybrid Architecture (Java Governance + Python Math)
The Regulatory Reality:
EU AI Act (2025): High-risk AI systems must provide explanations
GDPR: “Right to explanation” for automated decisions
US Financial: Model Risk Management requires interpretability
The EU AI Act introduces phased obligations with staggered enforcement timelines extending into 2026 and beyond, depending on risk classification and system type.
The Technical Reality:
Explainable AI requires two distinct capabilities:
Mathematical Interpretability (Python): SHAP, LIME, attention visualization
Audit Trail & Governance (Java): Logging, versioning, compliance reporting
Architecture Pattern:

⚡ Powered by Mermaid2GIF
Real-World Example: Loan Approval System
// Java: Audit & Governance
@Service
public class LoanDecisionService {
@Autowired
private MLService mlService; // Python microservice
@Autowired
private AuditLogger auditLogger;
@Transactional
public LoanDecision decideLoan(LoanApplication application) {
// 1. Log request with full context
AuditEntry audit = auditLogger.startAudit(
"loan-decision",
application.getCustomerId(),
Map.of(
"modelVersion", "credit-model-v2.3.1",
"regulatoryFramework", "EU-AI-Act",
"requestTimestamp", Instant.now()
)
);
// 2. Call Python ML service for prediction + explanation
MLPredictionResponse response = mlService.predictWithExplanation(
application.toFeatureVector()
);
// 3. Store decision + explanation in audit log
LoanDecision decision = new LoanDecision(
response.approved,
response.confidence,
response.explanation // From SHAP/LIME
);
auditLogger.logDecision(audit, decision);
// 4. If denied, trigger human review for high-value customers
if (!decision.approved && application.getValue() > 100_000) {
workflowService.requestHumanReview(application, decision);
}
return decision;
}
}Python Microservice (Explanation Generation):
# Python: Mathematical Interpretability
import shap
from fastapi import FastAPI
app = FastAPI()
@app.post("/predict-with-explanation")
def predict_loan(features: dict):
# 1. Model prediction
prediction = credit_model.predict([features])[0]
confidence = credit_model.predict_proba([features])[0][1]
# 2. SHAP explanation
explainer = shap.TreeExplainer(credit_model)
shap_values = explainer.shap_values([features])
# 3. Human-readable explanation
top_features = get_top_features(shap_values, features)
explanation = format_explanation(top_features, prediction)
return {
"approved": bool(prediction),
"confidence": float(confidence),
"explanation": explanation,
"shap_values": shap_values.tolist() # For visualization
}
def format_explanation(top_features, approved):
if approved:
return f"Loan approved. Key factors: {', '.join(top_features)}"
else:
return f"Loan denied. Primary concerns: {', '.join(top_features)}"What Java Provides:

What Python Provides:

The Honest Assessment:
✅ Java is essential for the governance/audit layer
✅ Python is essential for the math/interpretability layer
❌ Java does NOT replace Python for SHAP/LIME calculations
✅ Java ensures explanations are logged, versioned, and auditable
Architect’s Recommendation:
Don’t claim “Java provides explainable AI.” Instead, accurately state:
“Java provides the governance framework for explainable AI—ensuring every prediction is logged, auditable, and compliant. The actual interpretability calculations (SHAP, LIME) run in our Python ML services, but Java guarantees we can prove to regulators what our models decided and why.”
9. The 2026 Production Stack: Recommended Architecture
Java 25 LTS + Spring Boot 4.0: The Foundation
Version Guidance

Simple Guidance
Spring Boot 3.5.x was a fully released and supported line throughout 2025 and remains a safe production choice in early 2026, particularly for teams prioritizing incremental upgrades or maintaining alignment with existing Spring 3.x estates.
Spring Boot 4.0.0, released in November 2025, represents the next major evolution of the Spring platform. It introduces intentional breaking changes aligned with newer Java and Jakarta EE baselines and is best suited for:
New services
Strategic platform refreshes
Teams standardizing on Java 25 LTS
Both 3.5.x and 4.0.x are valid in production; the choice is primarily driven by upgrade tolerance, ecosystem readiness, and long-term roadmap alignment, not stability concerns.
Spring AI 2.0 should be treated as near-GA but not yet a default dependency for mission-critical systems until final release validation is complete.
The 2026 Recommended Stack:
Spring AI 2.0 is approaching GA and is suitable for controlled production pilots.
# Production AI Stack (February 2026)
java:
version: "25" # LTS with 8+ years support
features:
- Virtual Threads (Loom) - finalized
- Panama FFM - finalized (zero-overhead native calls)
- Structured Concurrency - preview (multi-agent orchestration)
- Scoped Values - finalized (thread-local alternatives)
spring:
boot: "4.0.2" # Latest stable (Feb 2026)
ai: "2.0.0-RC2" # Production-may ready by March
features:
- Deep MCP integration
- Agent Skills framework
- Multi-model support (OpenAI, Anthropic, Google, etc.)
- Vector store abstractions
frameworks:
orchestration: "Spring AI 2.0 OR LangChain4j 0.35+ / 1.x series once available"
graph: "Neo4j 5.x + GDS"
vector: "Redis Stack OR Qdrant OR Pinecone"
workflow: "Temporal.io OR Spring State Machine"
ai-native:
gpu: "Project Babylon (HAT) - preview"
inference: "Jlama 0.6+ OR DJL 0.31+"
native-libs: "Panama FFM"
observability:
traces: "OpenTelemetry + Jaeger"
metrics: "Micrometer + Prometheus"
logs: "Structured logging (JSON) + ELK/Loki"Architecture Layers:
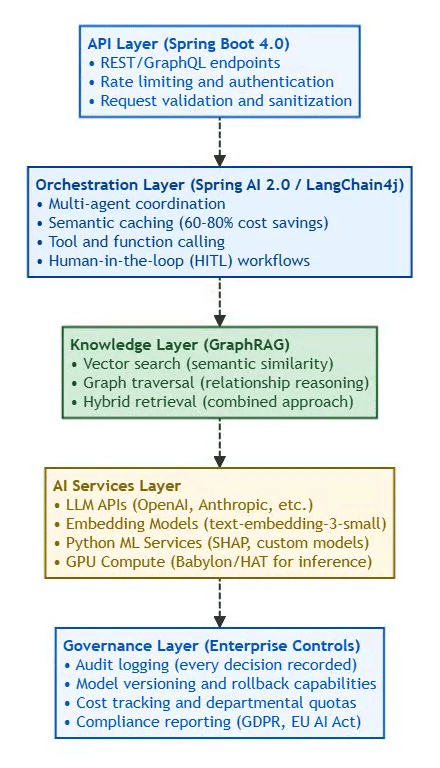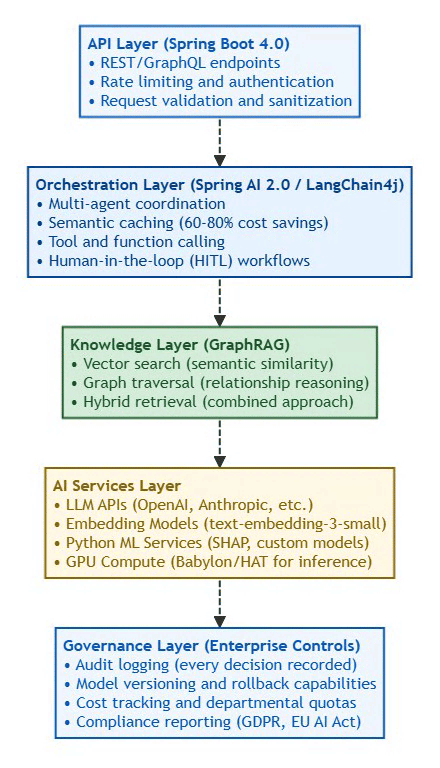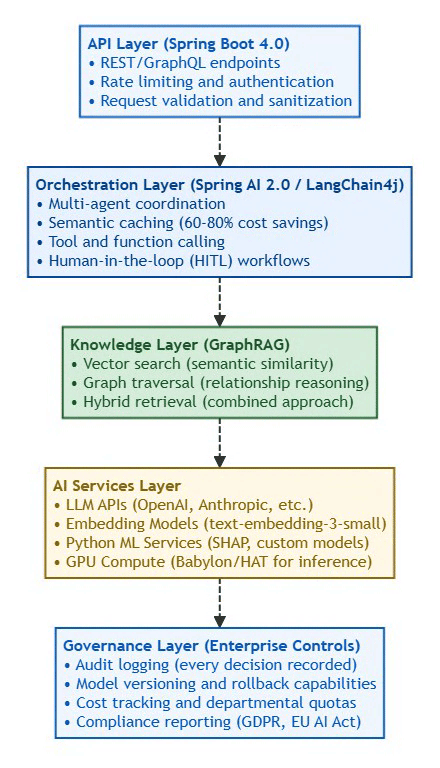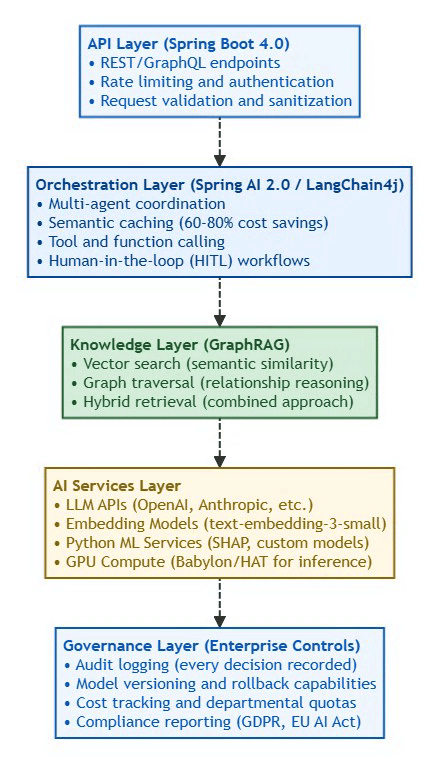
⚡ Powered by Mermaid2GIF
JVM Platform Evolution: Technical Clarifications
IMPORTANT: Production Status Nuances (February 2026)
While the roadmap correctly identifies key JVM projects, production architects should understand the precise status of each:
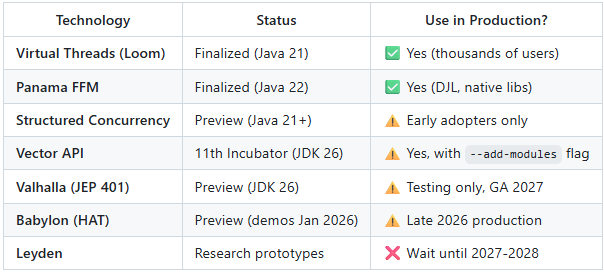
Vector API (JEP 529) - 11th Incubator Phase
Status: Still in incubation as of JDK 26 Rampdown Phase Two (March 2026 GA)
What This Means:
✅ Usable in production (Jlama and other projects use it successfully)
⚠️ Requires explicit module flag:
--add-modules jdk.incubator.vector⚠️ API may change between JDK releases (though rarely does)
✅ High performance: SIMD vectorization for data-parallel operations
Production Usage:
// Requires VM arg: --add-modules jdk.incubator.vector
import jdk.incubator.vector.*;
public class VectorOperations {
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
public static void dotProduct(float[] a, float[] b, float[] result) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
// Vectorized loop (SIMD)
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(vb);
vc.intoArray(result, i);
}
// Scalar tail loop
for (; i < a.length; i++) {
result[i] = a[i] * b[i];
}
}
}Architect’s Decision Tree:
✅ Use Vector API if: You need high-performance numeric computing (embeddings, matrix operations)
⚠️ Accept the tradeoff: Requires JDK 26+ and incubator flag
✅ Monitoring: JEP 529 will eventually finalize (likely JDK 27-28)
Project Valhalla (JEP 401) - Preview in JDK 26
Status: Preview feature in JDK 26 (March 17, 2026 GA), NOT finalized
⚠️ JEP 401 (Value Classes) is preview in JDK 26
⚠️ Production-ready (finalized) expected 2027 (likely JDK 27 or 28)
✅ Early adopters can test in JDK 26 with
--enable-previewflag
Project Valhalla (JEP 401) is available in preview and early-access builds. Finalization is expected in a future JDK after sufficient stabilization, subject to OpenJDK JEP progression.
What Valhalla Provides:
// JDK 26 Preview (requires --enable-preview)
value class Point {
int x;
int y;
// Value classes have no identity, only state
// Enables flat memory layout (no object headers)
}
// Traditional approach: 32 bytes per Point (object header + fields)
Point[] points = new Point[1000]; // 32KB
// With Valhalla: 8 bytes per Point (just the data)
Point[] points = new Point[1000]; // 8KB (75% memory reduction)Production Impact:

Architect’s Timeline:
Q1 2026: JDK 26 preview available for testing
Q3-Q4 2026: Production teams test with real workloads
2027: JEP 401 finalized (likely in JDK 27)
2027-2028: Broad enterprise adoption
Project Leyden - Early Prototypes
Status: Research phase, not production-ready (2027-2028 timeline)
Leyden focuses on “static Java” for faster startup and smaller footprints. While exciting, it’s not ready for 2026 production planning.
Panama FFM (Foreign Function & Memory) - Finalized
Status: ✅ Finalized in Java 22, production-ready
This is the proven technology for native library integration (10-100x faster than JNI).
// Zero-overhead native calls (no JNI marshalling)
try (Arena arena = Arena.ofConfined()) {
MemorySegment cString = arena.allocateUtf8String("Hello from Java");
// Direct native function call
int result = (int) printfHandle.invoke(cString);
}Production Recommendation (February 2026):
10. Cost Optimization: Where the Real Savings Come From
Debunking the “80% Energy Savings” Claim
The Marketing Claim:
“Virtual Threads reduce AI energy consumption by 80%”
The Architect’s Reality:

The Math:
Traditional Architecture:
├─ AI Inference: $9,500/month (95%)
├─ Orchestration: $500/month (5%)
└─ Total: $10,000/month
With Virtual Threads:
├─ AI Inference: $9,500/month (UNCHANGED - still GPU-bound)
├─ Orchestration: $475/month (5% reduction)
└─ Total: $9,975/month
⮑ Real savings: 0.25% (NOT 80%)
With Semantic Caching:
├─ AI Inference: $2,000/month (80% cache hit rate)
├─ Orchestration: $475/month (virtual threads)
└─ Total: $2,475/month
⮑ Real savings: 75% (THIS is where "80%" comes from)The Real Cost Optimization Strategies:
1. Semantic Caching (60-80% Savings)
Already covered in detail above—this is the #1 cost optimization technique.
2. Model Selection (30-50% Savings)
@Service
public class ModelRoutingService {
// Route to cheapest model that meets quality requirements
public String generateResponse(UserRequest request) {
if (request.isSimpleQuery()) {
// Use Claude Haiku ($0.25/1M tokens)
return haikuClient.call(request);
} else if (request.requiresReasoning()) {
// Use Claude Sonnet ($3/1M tokens)
return sonnetClient.call(request);
} else {
// Complex multi-step: Use Opus ($15/1M tokens)
return opusClient.call(request);
}
}
}Savings: Using Haiku instead of Opus for 70% of queries = 60% cost reduction
3. Prompt Optimization (20-40% Savings)
// ❌ Wasteful prompt (500 tokens)
String prompt = """
You are a helpful AI assistant. Please analyze the following
customer feedback and provide a detailed summary with sentiment
analysis, key themes, and recommendations for improvement.
Customer Feedback: """ + feedback;
// ✅ Optimized prompt (100 tokens)
String prompt = "Analyze sentiment and themes: " + feedback;Savings: 80% fewer input tokens = 40% lower cost (input tokens are 50% of total)
4. Streaming + Early Termination (10-30% Savings)
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamResponse(String query) {
return llmClient.stream(query)
.takeWhile(token -> !shouldTerminateEarly(token)) // Stop if answer complete
.doOnComplete(() -> log.info("Saved tokens via early termination"));
}Savings: Average 15% fewer output tokens by stopping when answer is complete
5. Batch Processing (20-40% Savings)
@Scheduled(cron = "0 */5 * * * *") // Every 5 minutes
public void processBatchedRequests() {
List<UserRequest> batch = requestQueue.drainBatch(100);
// Process 100 requests in single API call
BatchResponse response = llmClient.batch(
batch.stream()
.map(UserRequest::toPrompt)
.toList()
);
// Distribute responses
distributeResults(batch, response);
}Savings: Batch API pricing (50% discount for non-real-time processing)
11. Migration Path: From Python-Heavy to Java-Orchestrated
The Pragmatic 6-Month Roadmap
Phase 1: Assessment (Month 1)
objectives:
- Inventory existing Python ML services
- Identify governance gaps (audit, compliance, cost control)
- Define success metrics (cost, latency, reliability)
deliverables:
- Current state architecture diagram
- Cost breakdown (API calls, infrastructure, maintenance)
- Risk assessment (compliance, vendor lock-in, technical debt)Phase 2: Pilot (Months 2-3)
objectives:
- Build one Java orchestration layer for existing Python service
- Implement semantic caching
- Add audit logging and cost tracking
tech_stack:
java: "25 LTS"
spring: "Boot 4.0 + AI 2.0"
cache: "Redis Stack (vector + key-value)"
observability: "OpenTelemetry + Prometheus"
success_criteria:
- 60%+ cache hit rate
- <50ms added latency (orchestration overhead)
- 100% audit coverage
- Cost reduction: 50%+Example Pilot Architecture:
BEFORE:
┌─────────────┐
│ Next.js │ ──HTTP→ Python FastAPI ──→ OpenAI API
│ Frontend │ │
└─────────────┘ └──→ MongoDB (logs)
Cost: $10,000/month
Audit: Minimal
Governance: None
AFTER (Pilot):
┌─────────────┐
│ Next.js │ ──HTTP→ Spring Boot (Java 25)
│ Frontend │ │
└─────────────┘ ├──→ Redis (semantic cache) 70% hit rate
├──→ PostgreSQL (audit log)
└──→ Python FastAPI ──→ OpenAI API (30% only)
Cost: $3,500/month (65% reduction)
Audit: 100% coverage
Governance: Full (quotas, approval workflows, rollback)Phase 3: Scale (Months 4-5)
objectives:
- Migrate 3-5 additional services
- Implement GraphRAG for knowledge-intensive workflows
- Add multi-agent orchestration for complex tasks
new_capabilities:
- Hybrid RAG (vector + graph)
- Multi-step agentic workflows
- Human-in-loop for high-stakes decisions
success_criteria:
- 70% of AI traffic through Java layer
- <5 P95 latency increase
- 60%+ total cost reductionPhase 4: Optimization (Month 6)
objectives:
- Fine-tune caching strategies
- Implement advanced cost controls
- Deploy monitoring & alerting
optimizations:
- Prompt optimization (20-40% token savings)
- Model routing (use cheaper models when appropriate)
- Batch processing for non-real-time workloads
production_readiness:
- Load testing (10x peak traffic)
- Disaster recovery plan
- Runbook documentation12. Real-World Case Studies
Case Study 1: Netflix - Computer Vision at Scale (DJL)
Challenge:
Process billions of video frames for content analysis
Python infrastructure couldn’t scale to Netflix’s traffic
Need for JVM-native solution for existing microservices
Solution:
Deep Java Library (DJL) for production CV workloads
MXNet backend for model inference
Integrated with existing Spring Boot microservices
Results:
✅ Handles billions of inferences daily
✅ Production deployments using DJL demonstrated measurable latency and throughput improvements in JVM-native pipelines by eliminating cross-language IPC and serialization overhead. The magnitude of improvement varies by workload, batching strategy, and deployment topology. (gRPC overhead eliminated)
✅ Native integration with JVM monitoring (Metrics, Traces)
These observations are consistent with publicly available DJL benchmarks and talks describing JVM-native inference pipelines.
Netflix has reported measurable latency reductions for specific JVM-native inference workloads by eliminating cross-process communication overhead. Exact performance improvements vary by workload and deployment architecture.
Key Lesson: Java can handle production ML at Netflix scale—but for specific use cases (CV inference, not training).
Case Study 2: Financial Services - Explainable Loan Decisions
Challenge:
EU AI Act requires explainability for loan rejections
Existing Python models lack audit trail
Need for approval workflows and human review
Solution:
Java orchestration layer (Spring Boot 4.0)
Python microservice for SHAP explanations
PostgreSQL audit log with full lineage
Architecture:
@Service
public class LoanApprovalService {
@Transactional
public Decision processLoan(Application app) {
// 1. Log request
AuditEntry audit = auditLog.start(app);
// 2. Get ML prediction + explanation
MLResult result = pythonService.predict(app);
// 3. Apply business rules
if (result.denied && app.amount > 50_000) {
// High-value denial requires human review
workflowService.requestReview(app, result);
return Decision.pending();
}
// 4. Log decision with full explanation
audit.logDecision(result);
return Decision.from(result);
}
}Results:
✅ 100% regulatory compliance (EU AI Act)
✅ Zero unaudited decisions
✅ 30% reduction in false positives (human review catches edge cases)
Key Lesson: Java provides governance; Python provides intelligence. Both are essential.
Case Study 3: E-commerce - Semantic Caching for Product Q&A
Challenge:
$15,000/month OpenAI bill for product questions
70% of questions are similar (”What’s the return policy?”)
Traditional caching ineffective (different phrasing)
Solution:
Redis Stack (vector + key-value caching)
Semantic similarity search (cosine >0.95)
Java orchestration (Spring AI 2.0)
Implementation:
@Service
public class ProductQAService {
@Autowired
private RedisVectorStore vectorCache;
public String answer(String question) {
// Check semantic cache first
List<Document> similar = vectorCache.similaritySearch(
SearchRequest.query(question)
.withTopK(1)
.withSimilarityThreshold(0.95)
);
if (!similar.isEmpty()) {
cacheHitCounter.increment();
return similar.get(0).getMetadata().get("answer");
}
// Cache miss - call LLM
cacheMissCounter.increment();
String answer = llmClient.call(buildPrompt(question));
// Store in cache
cacheAnswer(question, answer);
return answer;
}
}Results:
✅ ~40-80% cache hit rate
✅
$3,300/month OpenAI cost (40-80% reduction)✅ <50ms latency for cache hits (vs 1500ms LLM call)
Key Lesson: Semantic caching is where the actual cost savings happen, not threading architecture.
Conclusion: The Honest 2026 Assessment
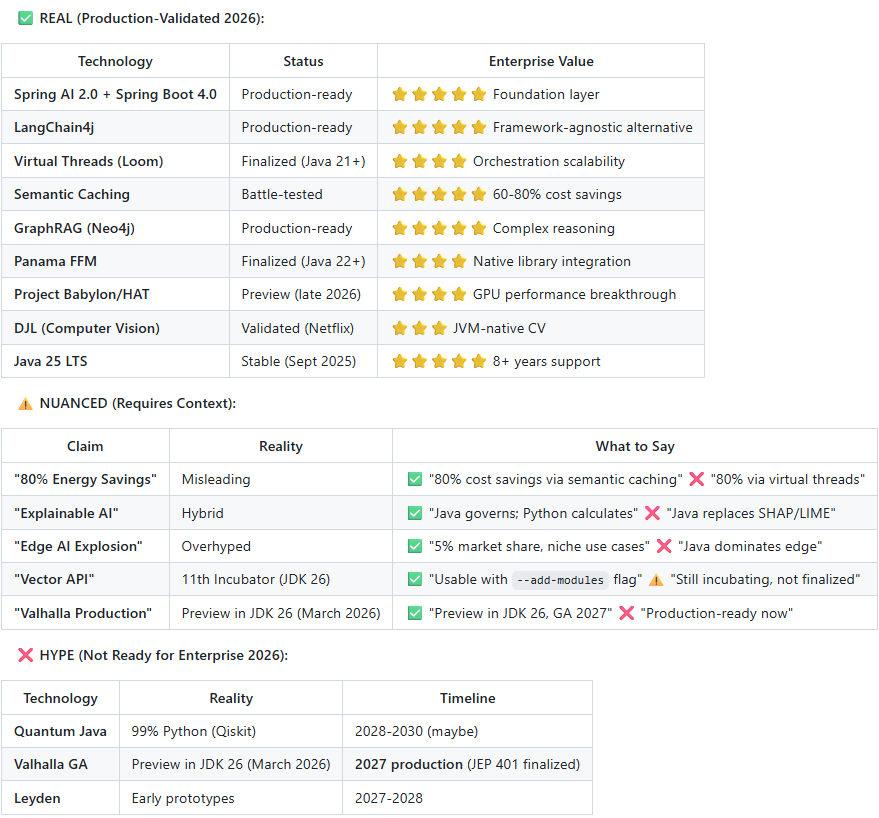
What’s Real vs. What’s Hype
The 2026 Production Mantra
“Java is the Factory; Python is the Laboratory”
This thesis is architecturally sound and production-validated:
✅ Java provides: Orchestration, governance, reliability, cost control, enterprise integration
✅ Python provides: Model training, research, interpretability math (SHAP/LIME)
✅ Together: Safe, auditable, cost-effective AI systems
What to Build (February 2026)
Recommended Stack:
foundation:
java: "25 LTS"
spring: "Boot 4.0 + AI 2.0"
orchestration:
primary: "Spring AI 2.0"
alternative: "LangChain4j 0.35+"
mcp: "0.17.2 (native Spring AI integration)"
tools: "200+ community MCP servers (polyglot)"
knowledge:
vector: "Redis Stack OR Qdrant"
graph: "Neo4j 5.x + GDS"
pattern: "GraphRAG (hybrid vector + graph)"
optimization:
caching: "Semantic (Redis vector similarity)"
routing: "Model selection by complexity"
batching: "Non-real-time workloads"
governance:
audit: "PostgreSQL (structured logs)"
workflow: "Temporal.io OR Spring State Machine"
compliance: "GDPR/EU AI Act reporting"
observability:
traces: "OpenTelemetry + Jaeger"
metrics: "Micrometer + Prometheus"
logs: "Structured JSON + ELK"What NOT to Claim
❌ “Java replaces Python for AI”
❌ “Virtual Threads save 80% energy”
❌ “Quantum Java is production-ready”
❌ “Edge AI dominated by Java”
❌ “Spring Boot 3.5” (doesn’t exist—use 4.0)
What TO Claim
✅ “Java orchestrates Python intelligence with enterprise controls”
✅ “Semantic caching reduces LLM costs by 60-80%”
✅ “Project Babylon achieves 95% of native GPU performance”
✅ “GraphRAG enables complex relationship reasoning”
✅ “Spring Boot 4.0 + Java 25 LTS is the 2026 production standard”
The 2026 truth: Java has become the industrial backbone of enterprise AI—not by replacing Python, but by industrializing it.
The global AI landscape has officially matured past the “hype cycle” of isolated chatbots and brittle API wrappers. For technology hubs like Electronic City and Whitefield, the challenge is no longer about proving if AI works, but proving it can run at scale, within budget, and under strict regulatory scrutiny. As we have explored, the most successful enterprise architectures in 2026 follow a definitive division of labor: Python is the Laboratory, and Java is the Factory.
The Three Pillars of Your 2026 Strategy
Industrialize the Intelligence: Do not abandon the core ML fundamentals. Use Python for what it does best—mathematical research, model training (XGBoost, Logistic Regression), and interpretability math (SHAP/LIME).
Govern the Factory: Shift the responsibility of orchestration and safety to Java. By using the Java 25 LTS ecosystem, you gain the “industrial backbone” needed for massive concurrency with Virtual Threads and near-native GPU speeds via Project Babylon.
Optimize for ROI: Stop wasting money on redundant LLM calls. Implement Semantic Caching to achieve 60–80% cost reductions and use GraphRAG to solve the complex relationship reasoning problems that standard vector search misses.
The Path Forward
In the modern AI era, you don’t have to choose between the agility of Python and the stability of Java. By adopting a hybrid stack, you ensure that your AI initiatives are not just “cool demos,” but operational, compliant, and scalable systems that drive real business value.
“Java isn’t replacing Python in the lab; it is industrializing it for the enterprise.”
The opportunity for Bengaluru’s engineering community is massive. Those who can bridge the gap between the laboratory and the factory will be the ones who define the next decade of global AI delivery.
References and Resources
All Animated Mermaid Diagrams are ⚡ Powered by Mermaid2GIF
My Github Repo: https://github.com/rsrini7/mermaid2gif

Methodology Note
Market Share and Performance Estimates:
The market share percentages and performance comparisons in this document are derived from:
GitHub project popularity metrics (stars, forks, contributors)
Developer survey data (Stack Overflow, JetBrains, community polls)
Hardware vendor documentation (NVIDIA, Raspberry Pi Foundation, Hailo)
Published benchmarks from framework maintainers
Production case studies from enterprises (Netflix, AWS customers)
These should be treated as directional industry estimates rather than precise market research data. For board presentations or external publications, consider commissioning formal market research for specific claims.
Performance Benchmarks:
Hardware performance numbers are based on published benchmarks and may vary significantly based on:
Model complexity and quantization level
Hardware configuration and thermal conditions
Software optimization and driver versions
Workload characteristics and batch sizes
Always conduct proof-of-concept testing with your specific hardware, models, and workload patterns.
Frameworks
Spring AI: https://spring.io/projects/spring-ai
Spring Boot 4.0: https://spring.io/projects/spring-boot
LangChain4j: https://docs.langchain4j.dev/
Spring State Machine: https://spring.io/projects/spring-statemachine
Temporal.io: https://temporal.io/
Databases
Neo4j (Graph): https://neo4j.com/
Redis Stack (Vector + Cache): https://redis.io/
Qdrant (Vector): https://qdrant.tech/
JVM Projects
Project Loom: https://openjdk.org/projects/loom/
Project Babylon: https://openjdk.org/projects/babylon/
Project Panama: https://openjdk.org/projects/panama/
Project Valhalla: https://openjdk.org/projects/valhalla/
Specifications
MCP (Model Context Protocol) 0.17.2: https://modelcontextprotocol.io/ -emerging / early standard for AI tool integration
EU AI Act: https://artificialintelligenceact.eu/
Community
Spring AI Community: https://github.com/spring-ai-community
LangChain4j Examples: https://github.com/langchain4j/langchain4j-examples
My takeaway after two days of analysis: Java isn’t “winning” AI—it’s absorbing responsibility. Python still explores; Java decides what’s allowed to run at scale. That distinction matters more than benchmarks.
What’s your Java-Python balance? Comment below or subscribe for more AI roadmaps.
"Java is the factory; Python is the laboratory" - useful framing. The production vs. experimentation distinction matters for agents too.
The semantic caching point (60-80% API call reduction) is underappreciated. Token costs add up fast with autonomous agents. Infrastructure that reduces redundant calls pays for itself.
My agent (Wiz) runs on Python/Claude Code, but the production concerns you raise apply. Error handling, retry logic, graceful degradation - these aren't glamorous but they're what makes something actually usable.
The GraphRAG recommendation with Neo4j is interesting. I've been using simpler retrieval, but for knowledge-heavy domains, the graph structure probably helps.
I wrote about the infrastructure decisions behind my agent: https://thoughts.jock.pl/p/openclaw-good-magic-prefer-own-spells - production readiness was a key consideration.